
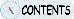
|
|
| Обозначение |
L(x|a,b) |
| Область значений |
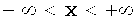 |
| Параметры | Параметр расположения a, параметр масштаба b > 0. |
| Плотность (функция вероятности) |
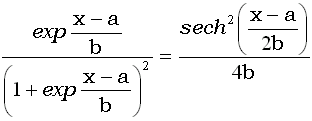 |
| Математическое ожидание | a |
| Дисперсия |
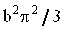 |
| Функция распределения |
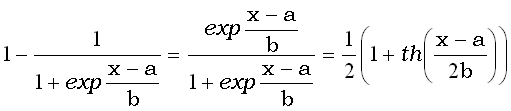 |
Нормальная функция распределения 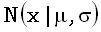 отличается от логистической
отличается от логистической 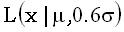 не более чем на 0.01.
Понятно, что для проверки гипотезы о принадлежности нашей выборки к одному из них требуются выборки непомерно большого объема.
Как, по-вашему, почему, все-таки, всюду используется нормальное распределение?
не более чем на 0.01.
Понятно, что для проверки гипотезы о принадлежности нашей выборки к одному из них требуются выборки непомерно большого объема.
Как, по-вашему, почему, все-таки, всюду используется нормальное распределение?
Пусть r– равномерно распределенная на отрезке [0,1] случайная величина.
Тогда случайная величина x,
подчиняющаяся логистическому распределению с параметром расположения a и параметром масштаба b, может быть получена стандартным способом – с помощью следующего соотношения:
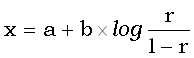 .
.
Не представляет никаких трудностей: используются лишь функции, входящие в стандартные библиотеки (как в Си), либо в сам язык (как в Паскале).
Для совсем ленивых все-таки привожу коды. Помните все же, что использованные стандартные функции работают с ограниченной точностью!
#ifndef __LOGISTIC_H__ /* To prevent redefinition */ #define ENTRY extern #define LOCAL static ENTRY double logisticDF(double x, double a, double b); ENTRY double inv_logisticDF(double q, double a, double b); #define __LOGISTIC_H__ /* Prevents redefinition */ #endif /* Ends #ifndef__LOGISTIC_H__ */ |
#include <assert.h>
#include <math.h>
double logisticDF(double x, double a, double b)
{
assert(b > 0);
return 1./(1+exp((a-x)/b));
}
double inv_logisticDF(double q, double a, double b)
{
assert(b > 0 && q > 0 && q < 1.);
return a-b*log(1./q-1);
}
#ifdef TEST
#include <iostream.h>
void main(void)
{
double a, b;
while (1) {
cout << "\n\n\rEnter a: ";
cin >> a;
if (a <= 0)
break;
cout << "Enter b: ";
cin >> b;
for(double x=-8; x < 8; x += 0.32)
{
double y=logisticDF(x, a, b);
double z=inv_logisticDF(y, a, b);
cout << "x=" << x << "\tl=" << y << "\ti=" << z << endl;
}
}
}
#endif
|
Дата последней модификации: 25 октября 2000 г.